Troubleshooting
Note
This page explains the frequently encountered issues in Chef Automate High Availability (HA) functionality and the steps to resolve them.
Issues and Solutions
Post Automate HA deployment if the chef-server service is in a critical state
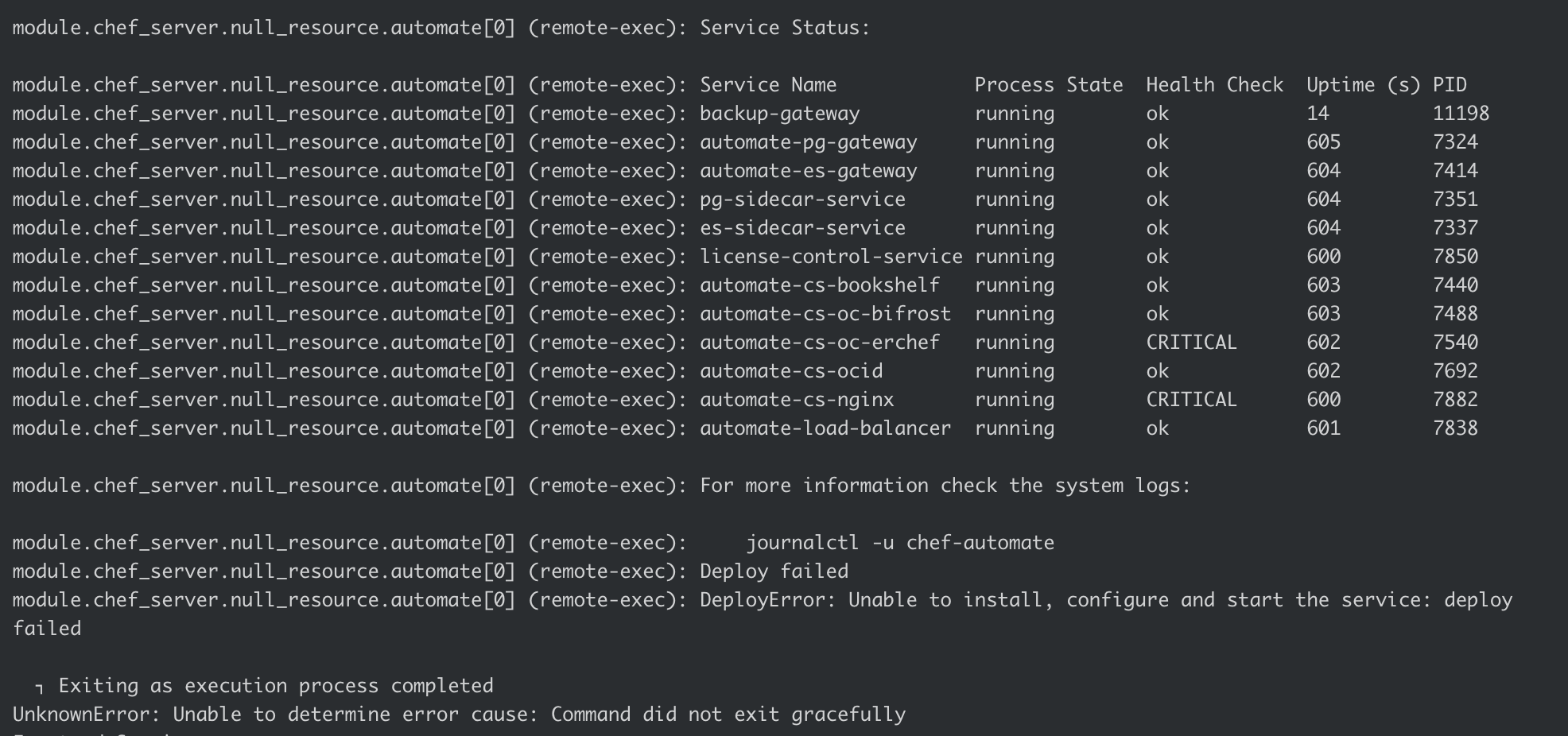
Solution
- First we can check if Automate UI is opening via browser if it open’s then we can try to hit the curl request to the Automate FQDN from the Chef Infra Server node.
curl --cacert /path/to/fqdn-rootca-pem-file https://<AUTOMATE_FQDN>- The above request will verify the authenticity of the server’s SSL certificate (FQDN RootCA) against Automate FQDN.
- In case if it gives any error, then we have make sure that the
RootCAis valid or not.
- The above curl request will work in case if ssl is terminating at load balancer.
- In case of ssl is not terminating at the Load Balancer, we need to patch the certificate to the Automate via cert-rotate command.
- The above steps required the
private-key,public-keyandroot-ca. - If the above steps did not work, Run the command on Automate HA chef-server node
journalctl --follow --unit chef-automate - If getting a 500 internal server error with the data-collector endpoint, it means that Chef Infra Server is not able to communicate to the Chef Automate data-collector endpoint.
To make the service healthy, ensure the chef server can curl the data collector endpoint from the chef server node.
Issue: Database Accessed by Other Users
Level=error msg="Failed to restore services" backup_id=20210914082922 error="failed to import database dump from automate-cs-oc-erchef/pg_data/automate-cs-oc-erchef.fc: error dropping database \"automate-cs-oc-erchef\": pg: database \"automate-cs-oc-erchef\" is being accessed by other users" restore_id=20210914130646
The restore command fails when other users or services access the nodes’ databases. This happens when the restore service tries to drop the database when some services are still running and are referring to the database.
Solution
- Stop the services on all the frontend
chef-automate stop.
Stopping the service on all frontend node will able to drop the database while running the restore command.
Issue: Cached Artifact not found in Offline Mode
The cached artifact does not exist in offline mode. This issue occurs in an air gap environment when a package tries to pull any dependency components or details from the internet.
"level=error msg=""Failed to restore services"" backup_id=20210913105135 error=""msg=\""failed to install\""
"package=chef/back up-gateway/0.1.0/20210817045252 output=0 Enabling feature : OFFLINE_INSTALL\n Installing chef/backup - gateway/0.1.0/20210817045252\nxxx\nxxx Cached artifact not found in offline mode : chef/backup gateway/0.1.0/20210817045252\nxxx\n: exit status 1"" restore_id=20210913135429 Sep 13 13:54:48 ip-172- 31-64- 42 hab[7228]: deployment-service.default(O): time=""2021-09- 13T13:54:48Z"" level=info msg=""finished streaming call with code OK"" grpc .code=OK grpc .method=DeployStatus grpc .request.deadline=""2021-09-13T15:54:29Z"""
"grpc .service=chef .automate.domain .deployment.Deployment grpc.start_time=""2021-09- 13T13:54:47Z""
grpc .time_ms=1229.028 span .kind =server system=grpc
Solution
Use the --airgap-bundle option and the restore command. Locate the name of the airgap bundle from the path /var/tmp. For example, the airgap bundle file name, frontend-4.x.y.aib.
Command Example
chef-automate backup restore s3://bucket\_name/path/to/backups/BACKUP\_ID --patch-config </path/to/patch.toml> --skip-preflight --s3-access-key "Access\_Key" --s3-secret-key "Secret\_Key" --airgap-bundle /var/tmp/<airgap-bundle>
Issue: Existing Architecture does not Match the Requested
The existing architecture does not match the requested issue when you have made AWS provisioning. Again, you are trying to run the chef-automate provision config.toml --airgap-bundle automate.aib command.
Solution
Execute the following command from the bastion host from any location:
sed -i 's/deployment/aws/' /hab/a2\_deploy\_workspace/terraform/.tf\_archsed -i 's/architecture "deployment"/architecture "aws"/' /hab/a2\_deploy\_workspace/a2ha.rb
Issue: Unable to Determine the Bucket Region
When Chef Automate instances cannot locate the S3 bucket, the following error is displayed:
BackupRestoreError: Unable to restore backup: Listing backups failed: RequestError: send request failed caused by: Get "https://s3.amazonaws.com/a2backup?delimiter=%2F&list-type=2&prefix=elasticsearch%2F"
Solution
Ensure that the access key, secret key, and endpoints are correct. If you are using on-premises S3 (replica of s3) for backup and facing issues with restore, attach the s3-endpoint with the chef-automate backup restore command. For example:
chef-automate backup restore s3://bucket_name/path/to/backups/BACKUP_ID --skip-preflight --s3-access-key "Access_Key" --s3-secret-key "Secret_Key" --s3-endpoint "https://s3.amazonaws.com"
In the above command we need to update --s3-access-key, --s3-secret-key and --s3-endpoint
Issue: HAB Access Error
The hab user does not have read, write, or executive privileges on the backup repository.
Solution
Execute the following command to grant permission to the user.
sudo chef-automate backup fix-repo-permissions <path>
Issue: bootstrap.abb scp Error
While trying to deploy Chef Automate HA multiple times on the same infrastructure, the bootstrap.abb file is not created again as a state entry from past deployment blocks the creation. The possible error looks like as shown below:
Error running command 'scp -o StrictHostKeyChecking=no -i /root/.ssh/a2ha-hub cloud-user@<ip>5:/var/tmp/bootstrap.abb bootstrap8e143d7d.abb': exit status 1. Output: scp: /var/tmp/bootstrap.abb: No such file or directory
Solution
- Log in to the Bastion host.
- Move to the directory,
cd /hab/a2_deploy_workspace/terraform/. - Execute the following commands:
terraform taint module.bootstrap_automate.null_resource.automate_pre[0]
terraform taint module.bootstrap_automate.null_resource.automate_pre[1]
terraform taint module.bootstrap_automate.null_resource.automate_pre[2]
terraform taint module.bootstrap_automate.null_resource.automate_post[0]
terraform taint module.bootstrap_automate.null_resource.automate_post[1]
terraform taint module.bootstrap_automate.null_resource.automate_post[2]
Issue: Deployment or Upgrade Fails as UnknownError
While trying to deploy or upgrade Chef Automate HA, if the command did not exit gracefully, the possible error looks like as shown below:
Exiting as execution process completed
UnknownError: Unable to determine error cause: Command did not exit gracefully.
- Examine the logs from bastion (/hab/a2_deploy_workspace/logs/a2ha-run.log) or from frontend/backend nodes in svc-load.log (or) automate-ctl.log in /hab/var/automate-ha/
- If you found that
sysctl: command not found, follow the below steps:
Solution
- In logs, check for which module prompted an error.
- SSH into the node and check if the
sysctlutility is available by runningsysctl -a. - If
Command 'sysctl' not found, try installing the pkg.
Issue: knife-ec-restore during migration: Failed to restore synchronous operations
- While running the restore command, if you are getting this error in logs:
Failed to restore synchronous operationsfollow either of the methods below.
Solution 1
Go to any Automate Node in HA:
- Run the following command to get all the snapshots:
curl -k -X GET -s http://localhost:10144/_snapshot/_all?pretty
- One by One, delete all the snapshots using the below command:
curl -k -X DELETE -s http://localhost:10144/_snapshot/<snapshot_name>
Example:
curl -k -X DELETE -s http://localhost:10144/_snapshot/chef-automate-es6-event-feed-service
Alternatively, You can delete all the snapshots at once by using the below script, by updating the indices:
indices=(
chef-automate-es6-automate-cs-oc-erchef
chef-automate-es6-compliance-service
chef-automate-es6-event-feed-service
chef-automate-es6-ingest-service
)
for index in ${indices[@]}; do
curl -XDELETE -k -H 'Content-Type: application/json' http://localhost:10144/_snapshot/$index --data-binary @- << EOF
{
"type": "s3",
"settings": {
"bucket": "<YOUR-PRIMARY-CLUSTER-BUCKET-NAME>",
"base_path": "elasticsearch/automate-elasticsearch-data/$index",
"region": "<YOUR-PRIMARY-CLUSTER-REGION>",
"role_arn": "",
"compress": "false"
}
}
EOF
done
Solution 2
Log in to the OpenSearch dashboard
Run this query: GET _snapshot/_all to get all the snapshots.
Delete all the snapshots using this query: DELETE _snapshot/<snapshot name>
For example: DELETE _snapshot/chef-automate-es6-event-feed-service
Issue: knife SSL cert while setting up workstation during migration
In the case of HA setup, while doing knife ssl fetch, if the certificate fetched is for the domain \*.chefdemo.net, follow the below steps when you run knife ssl check.
Solution
Go to route 53 chefdemo.net
Create record as recordname.eng.chefdemo.net
CNAME with value HA URL: ec2-url.region.compute.amazonaws.com
Provide
https://<record-name>while running knife ssl check. E.g.,knife ssl check https://<record-name>.Log in to the Opensearch dashboard
Run this query: GET _snapshot/_all to get all the snapshots.
Delete all the snapshots using this query: DELETE _snapshot/
For example: DELETE _snapshot/ chef-automate-es6-event-feed-service
Issue: rename /tmp/temp2137181075 automate.config.toml: invalid cross-device link
This issue arises because the mv operation attempts to move a file between distinct filesystems. This process is disallowed due to the ‘invalid cross-device link’ error. It’s triggered when trying to execute file operations across filesystem boundaries.
Solution
We have noticed that resolving commands that lead to such errors is straightforward. Change the directory from which they are executed. Before reapplying the command, switch the directory to /hab:
cd /hab